If you are serious about ecommerce growth, you cannot treat product data as a back office chore anymore. Your catalog is now read by schema markup AI agents, search engines, and marketplaces that decide what surfaces and what stays invisible.
In my work with brands, I have seen clean product metadata outperform clever ad creatives. This article walks through how to structure JSON-LD product schema, fix weak product metadata, and build an inventory setup that agents can trust.
Summary: How to make your product data agent ready
If you want a short version, here it is. Schema markup AI agents need structured, consistent product metadata so they can match, price, and recommend your products without guessing.
At a minimum, every key SKU should expose a valid JSON-LD product schema block using the schema.org Product and Offer types. That block needs accurate identifiers (SKU plus GTIN or similar), current price, currency, and availability that reflects real inventory. It also has to match what a human sees on the page.
Think of this as SEO for machines that shop on your customer’s behalf. Get the basics right, then layer in richer fields like shipping details, returns, and variant logic.
Combine that with live inventory and pricing sync, regular validation, and you have the foundation for agent-friendly commerce. If you want to see how this connects to the wider journey, I break down the buying flow on How AI Agents Shop.
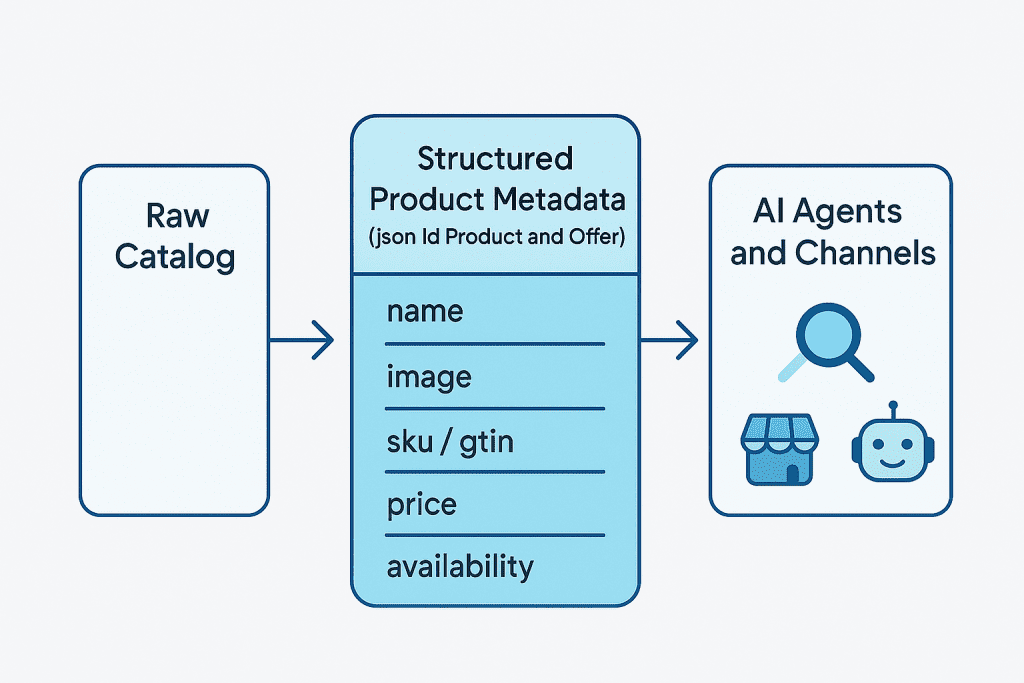
Why schema.org and JSON-LD are the language of agents
Most marketers still see structured data as a way to win rich snippets. That is already outdated. Today, schema markup is the language your catalog uses to communicate with agents, marketplaces, and partner platforms.
Google recommends json ld as the preferred format for Product markup in their own Google for Developers guides. Json ld sits inside a script tag, separate from your HTML layout. That means engineering teams can evolve design without breaking the logic agents rely on.
Here is how the main data formats compare in practice.
| Format | Typical Use Case | Pros | Cons |
|---|---|---|---|
| JSON LD | Modern ecommerce sites and apps | Clean, separate from HTML, easy to parse | Requires intent to implement correctly |
| Microdata or RDFa | Older templates, mixed in HTML | Inline with content | Hard to maintain at scale |
| XML or EDI feeds | B2B, legacy ERPs, marketplaces | Standardized for enterprise workflows | More complex parsers and transformations |
In most e-commerce builds I see now, JSON is the “inside language” too. Product feeds, APIs, and internal services talk json. That makes JSON-LD product schema a natural bridge between your frontend and the internal product brain that powers agents.
If you are thinking about the Business-to-Agent (B2A) strategy, structured product data is the first system you need to make boring, predictable, and reliable. I go deeper into this shift in Optimization for B2A, and in the pillar resource The Complete Guide to B2A Commerce [Business to Agents]: Preparing Your Ecom Brand for the AI-First Era.
A simple way to frame it. Every product page should answer three machine questions fast:
- What is this item, and how is it identified globally
- What does it cost right now, in which currency, and under what conditions
- Is it actually available to buy
Your schema.org Product and Offer markup is where those answers live.
Product metadata best practices in a world of agents
Here is the uncomfortable truth. Most catalogs are incomplete, inconsistent, or optimized only for human copywriting. That is fine for human visitors, but weak for agents that prefer structure over adjectives.
I usually start with a simple grid that product and dev teams can align on.
| Layer | Required Fields | Recommended Fields |
|---|---|---|
| Identity | name, sku, gtin (or EAN, UPC, ISBN, MPN) | brand as an Organization, model, productID |
| Presentation | image, description | category, color, size, material |
| Offer and price | price, priceCurrency, availability | itemCondition, priceValidUntil, url |
| Experience and trust | shippingDetails, hasMerchantReturnPolicy, reviews |
A few practical notes from real projects.
First, always combine local and global identifiers. Let your internal SKU do its job for operations. Add GTIN, EAN, UPC, or ISBN so agents can match your product across retailers. Platforms like ChannelEngine and similar feed tools are built around these identifiers for a reason.
Second, keep the description useful but not fluffy. An agent does not care that a hoodie is “perfect for cozy nights” but it will use material, fit, care instructions, and sizing hints to match a user request. Think attributes, not adjectives.
Third, do not forget the boring business details. Shipping cost ranges, delivery windows, and return policies influence whether an agent recommends you or a competitor. Google has added specific properties for shipping and returns in their structured data recommendations, and those fields feed into many ranking and recommendation models.
If you view your catalog through the lens of How AI Agents Shop, you start to see every missing field as friction in their decision tree.
Real-time inventory and pricing sync, or why static feeds fail
Agentic commerce is not polite. Agents do not care that your feed updates once per day if a user asks for “only items in stock that can arrive by Friday”. They expect fresh data.
In my experience, three flows matter more than anything else.
| Flow | Target Latency | Owner |
|---|---|---|
| Inventory changes | Seconds to a few minutes | Operations or backend |
| Price and promotions | Minutes | Pricing or marketing |
| Catalog changes | Hours or daily | Product or merchandising |
Modern inventory tools and product feed platforms offer event-based sync. When stock levels change, an event fires, and connected feeds or APIs update downstream data. Providers in this space, such as the feed management tools you see mentioned in ecommerce blogs, all push toward this event model.
From an AI agent perspective, the impact is simple. If your availability field in Offer schema is stale, agents will learn that your data is unreliable. They may downgrade your products in their internal ranking, even if your brand or price is strong.
I encourage teams to run a “truth audit” regularly. Pick a subset of SKUs. Compare what the website shows, what the structured data says, what your primary product feed exports, and what your internal ERP holds. Any mismatch is a risk.
This is also where B2A thinking becomes practical. When you design for continuous, real time sync, you are not only sending better data to Google or marketplaces. You are building an internal product information layer that any agent can plug into later, whether that is a shopping assistant, a service bot, or some custom tool described in Optimization for B2A.
Common schema markup mistakes that quietly break journeys
Most schema issues are not exciting. They are small mismatches that compound over time and confuse agents.
Here are the patterns I see again and again.
- Missing required Offer fields
Product schema is there, but Offer is missingprice,priceCurrency, oravailability. Without those three, no agent can safely treat the item as purchasable. - Wrong data types
Price values like"€49.99"instead of"49.99"break validation. Availability values written as"in stock"instead of the proper"https://schema.org/InStock"URI do the same. Google’s structured data tools and the Schema Markup Validator both complain about this. - Currency confusion
Leaving outpriceCurrencyor using"Dollars"instead of"USD"sounds obvious, yet I see it inside real catalogs. When agents have to guess the currency, they will often skip the item. - Contradicting page content
My favorite debugging step is to compare what the schema block says to what a human sees. If the schema price is 29.99 but the page shows 39.99, or if the schema availability is InStock while the page says “Out of stock”, you are sending conflicting signals to Google and to any agent scraping your page. - Misusing PreOrder and BackOrder
PreOrder is for products that do not exist yet but have a known release date. It is not a label for “we will get more stock eventually”. UseBackOrderfor that case and specify realistic expectations.
I like to treat these issues as a hygiene layer. Fix them once, add automated checks, and you reduce a whole class of invisible failures. When you are mapping a longer Business to Agents roadmap, as described in The Complete Guide to B2A Commerce [Business to Agents]: Preparing Your Ecom Brand for the AI-First Era, this hygiene work pays off for years.
A practical validation checklist for json ld product schema
Validation is where strategy meets discipline. Without it, even the best schema design slowly drifts out of sync as teams ship new templates, landing pages, and experiments.
I usually split validation into three layers.
1. Page level validation
This is your first line of defense.
- Use Google’s Rich Results Test for key product templates
- Check that required Product and Offer fields are detected
- Confirm that visible price, currency, and availability match structured data
You can bake this into QA for every new product page type, not every single SKU.
2. Sitewide structured data audits
Here you look for patterns, not individual bugs.
Tools like Sitebulb, Screaming Frog with the structured data extraction module, or specialized schema scanners can crawl your site and flag patterns. For example, “5 percent of product pages do not have Offer schema”, or “pages with variant X template are missing GTIN”.
A simple reporting table helps ownership.
| Check | Tool or Method | Owner | Frequency |
|---|---|---|---|
| Required Product and Offer properties | Crawler plus schema rules | SEO or growth | Monthly |
| Identifier coverage (GTIN, SKU, MPN) | Feed export inspection | Ecommerce lead | Quarterly |
| Variant and AggregateOffer implementation | Template review | Dev lead | At changes |
3. Feed and API validation
Finally, treat your product feeds and APIs as first class citizens. Agents will often consume those directly through integrations, not your HTML.
Run spot checks on your main product feed. Make sure the same identifiers, prices, and availability values match your onsite schema and the live page. If you are experimenting with AI shopping assistants or agent platforms, this is where they will plug in, similar to how described in How AI Agents Shop.
Validation is not glamorous work, but it is one of those compounding habits. Once it is in place, every new campaign, integration, or marketplace launch stands on more solid ground.
Q&A: Key questions on schema markup and agents
Q: What is json ld product schema in simple terms?
A: It is a structured block of data on your product page that describes your item in a machine readable way. It uses the schema.org vocabulary, usually inside a script tag, so agents and search engines can understand identity, price, and availability without guessing.
Q: How do agents actually use product metadata when shopping for users?
A: Agents parse your schema to find products that fit a query, such as “running shoes under 120 euros that deliver in two days”. They filter by price, currency, availability, and sometimes by attributes like size or material. Then they rank options using extra signals such as reviews, delivery promises, and brand.
Q: Do I need real time inventory sync for smaller catalogs?
A: If you change stock and prices rarely, daily feeds can work for now. Still, I recommend planning for faster sync because user expectations are rising. The moment you introduce flash sales, preorders, or multi channel selling, near real time updates stop being a nice to have and become part of your B2A readiness.
Conclusion: Product data as a growth channel, not a backend task
When I look at where ecommerce is heading, one pattern keeps repeating. Brands that treat product data and schema markup as a growth channel pull ahead. They are easy to understand for humans and for the growing layer of agents that mediate discovery and purchase.
You do not have to rebuild everything at once. Start by stabilizing your schema.org Product and Offer markup, with correct identifiers and live availability. Add a realistic validation routine. Then move toward richer metadata, cleaner feeds, and event based sync, in line with the direction I describe in Optimization for B2A.
If you want to see how this plays out from the shopper’s side, connect this article with the journey map in How AI Agents Shop. Together, they outline a simple idea. In an AI first commerce world, the brands that are easiest to read become the brands that are easiest to buy.
Quick Knowledge Check
Question 1: Which combination of fields is most critical for a valid purchasable offer?
Question 2: Why is json ld usually the best format for product schema on modern stores?